网站JS文件抓取工具
jjjjjjjjjjjjjs简介
针对WebPack站点,本工具能够爬取网站JS文件,通过分析获取接口列表,并自动结合指纹识别和Fuzz技术来获取正确的API根。用户可以指定API根地址,适用于前后端分离项目,以便指定后端接口地址。本工具可以根据有效的API根组合爬取到的接口,进行自动化请求,从而发现未授权访问和敏感信息泄露。它还能显示API响应,帮助用户定位敏感信息、敏感文件和敏感接口。此外,本工具支持批量模式,以及对需要认证的接口进行自动尝试Bypass。
原理流程图
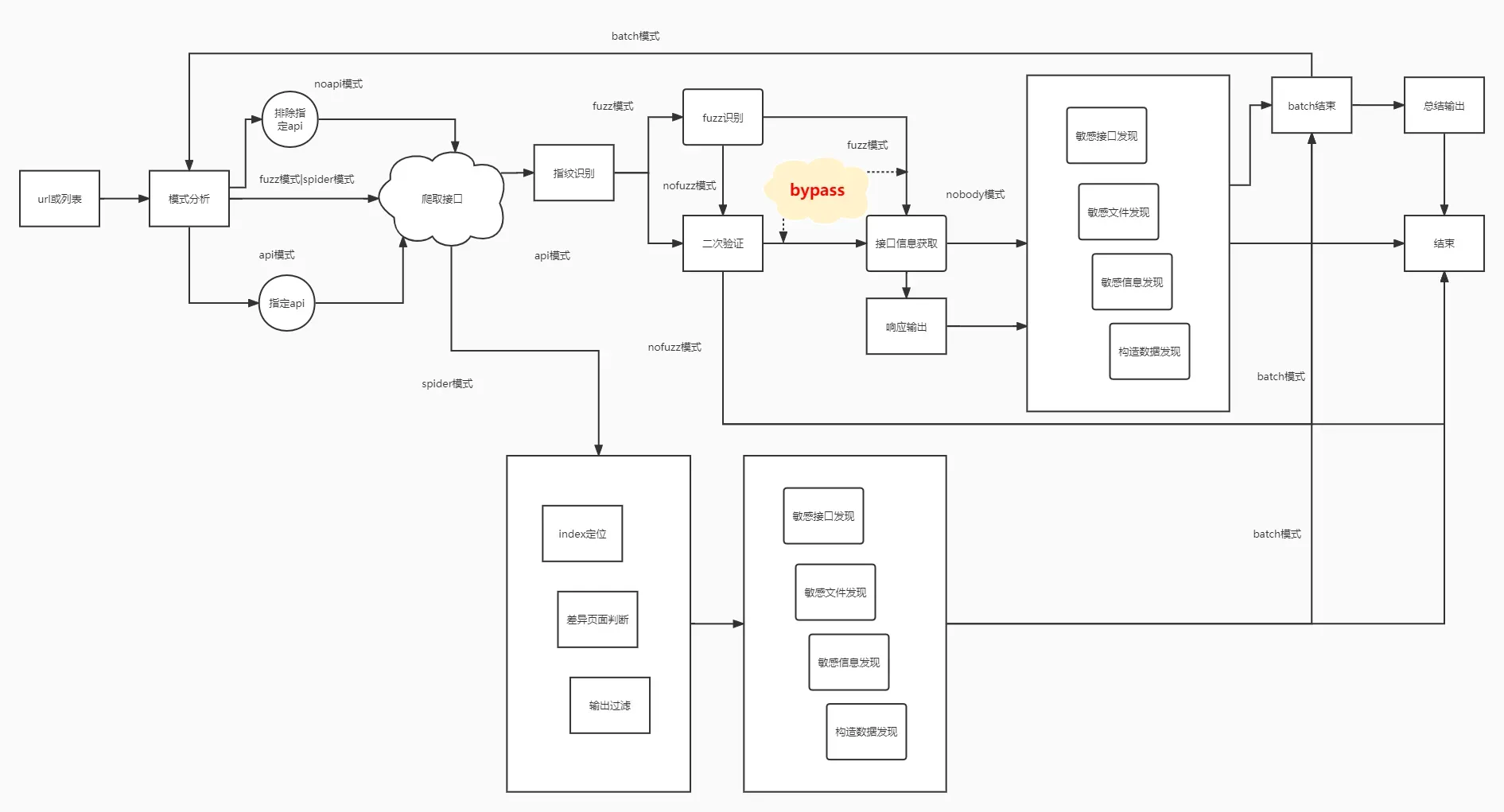
使用
环境:
python3.8
安装依赖:
pip3 install -r requirements.txt使用方式
使用方式:python3 jjjjjjjs.py url|urlfile [fuzz|api] [noapi] [nobody|nofuzz] [cookie] [header] [danger] [bypass] [output] [thread] [proxy] [flush] [deep]url|file: 目标urlfuzz: 自动fuzz接口api: 用户指定api根路径 fuzz|api e.g. api=/jeecg-boot 或 api=http://api.test.com/rootnoapi: 排除输入的指定api e.g. noapi=/system,/worker,/apinobody: 禁用输出响应body nobody|nofuzznofuzz: 仅获取有效api,无后续响应获取cookie: 设置cookie e.g. cookie='username=admin'header: 设置header e.g. header='X-Forwarded-For: localhost\nX-Access-Token: eyJxxxxx'danger: 解除危险接口限制bypass: 对500 401 403 进行bypass测试output: 输出到文件 (txt) e.g. output='dest.txt'thread: 线程数 e.g. thread=200proxy: 设置代理 (仅指定proxy时, 自动设置代理到http://127.0.0.1:8080) e.g. proxy='http://127.0.0.1:8080'flush: 清除项目历史记录, 重新爬取deep: 深度模式(一般不需要开启), 开启后爬取深度上限:URL 2层 JS 3层,同源URL 3层, 同源JS 5层debug: 展示更多信息目标参数的位置固定在参数第一位,其他参数不限制出现位置注意: 目标参数的位置固定在参数第一位,其他参数不限制出现位置
示例
爬取模式
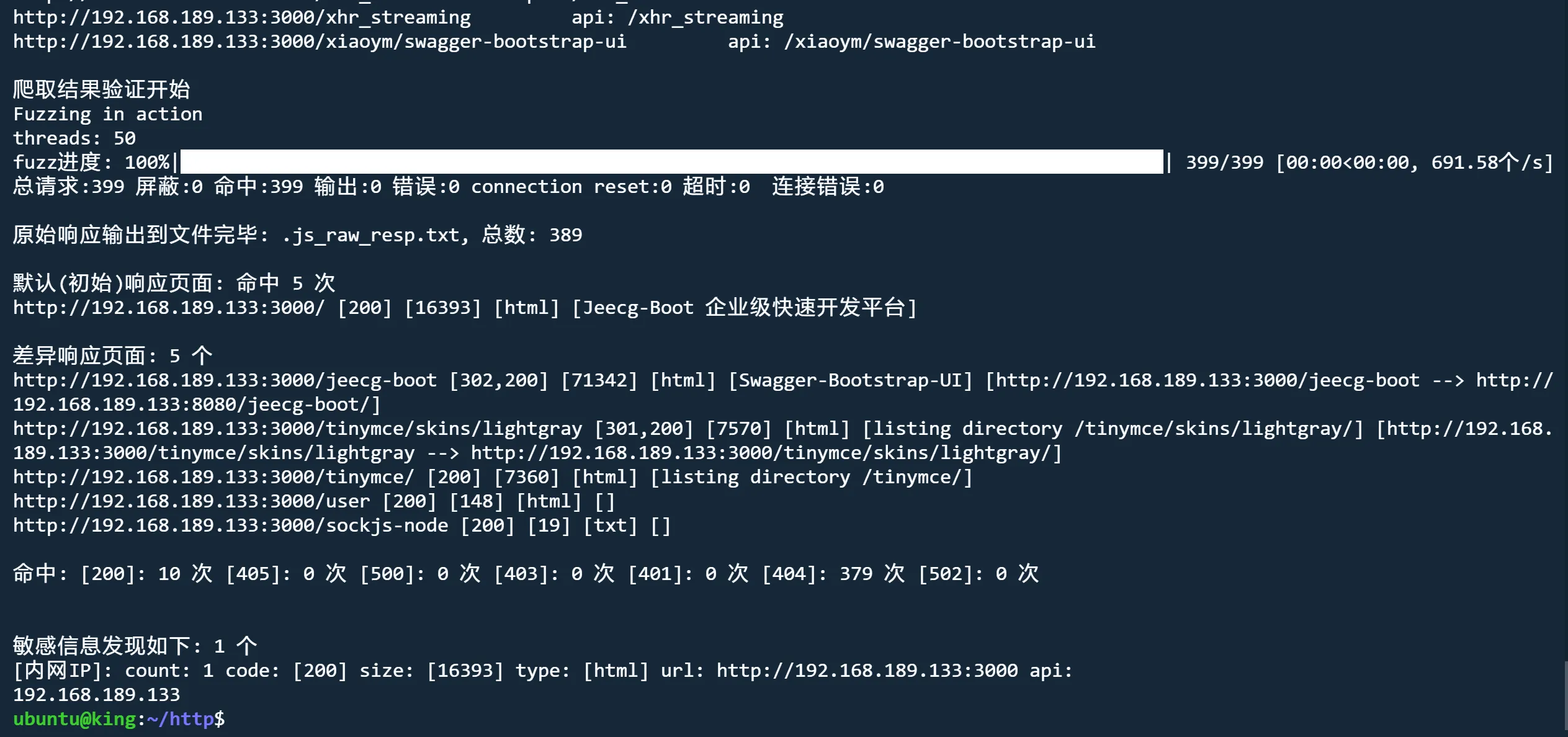
python3 jjjjjjjjjjjjjs.py http://192.168.189.133:3000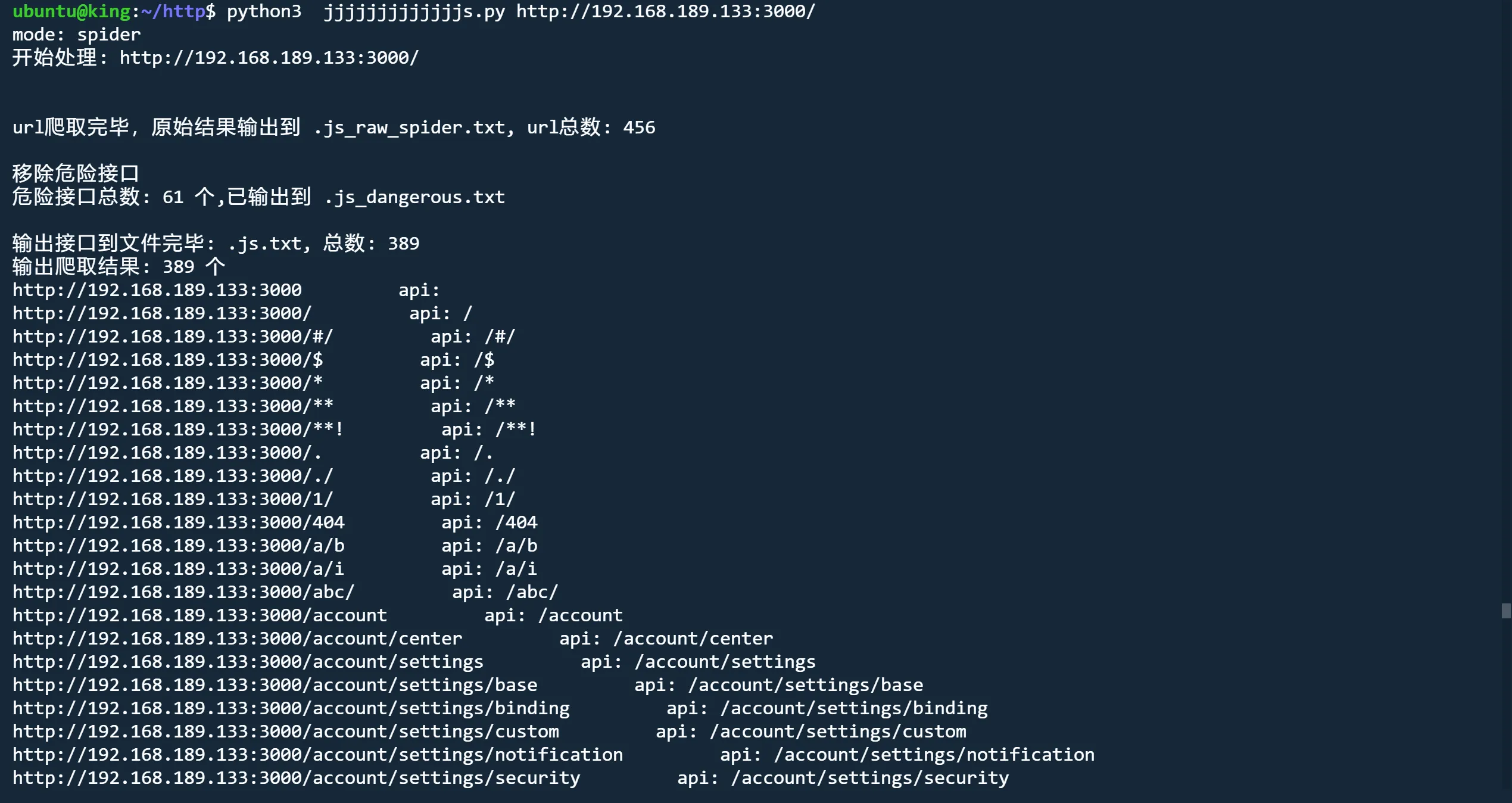
fuzz模式 nobody
python3 jjjjjjjjjjjjjs.py http://192.168.189.133:3000 fuzz nobody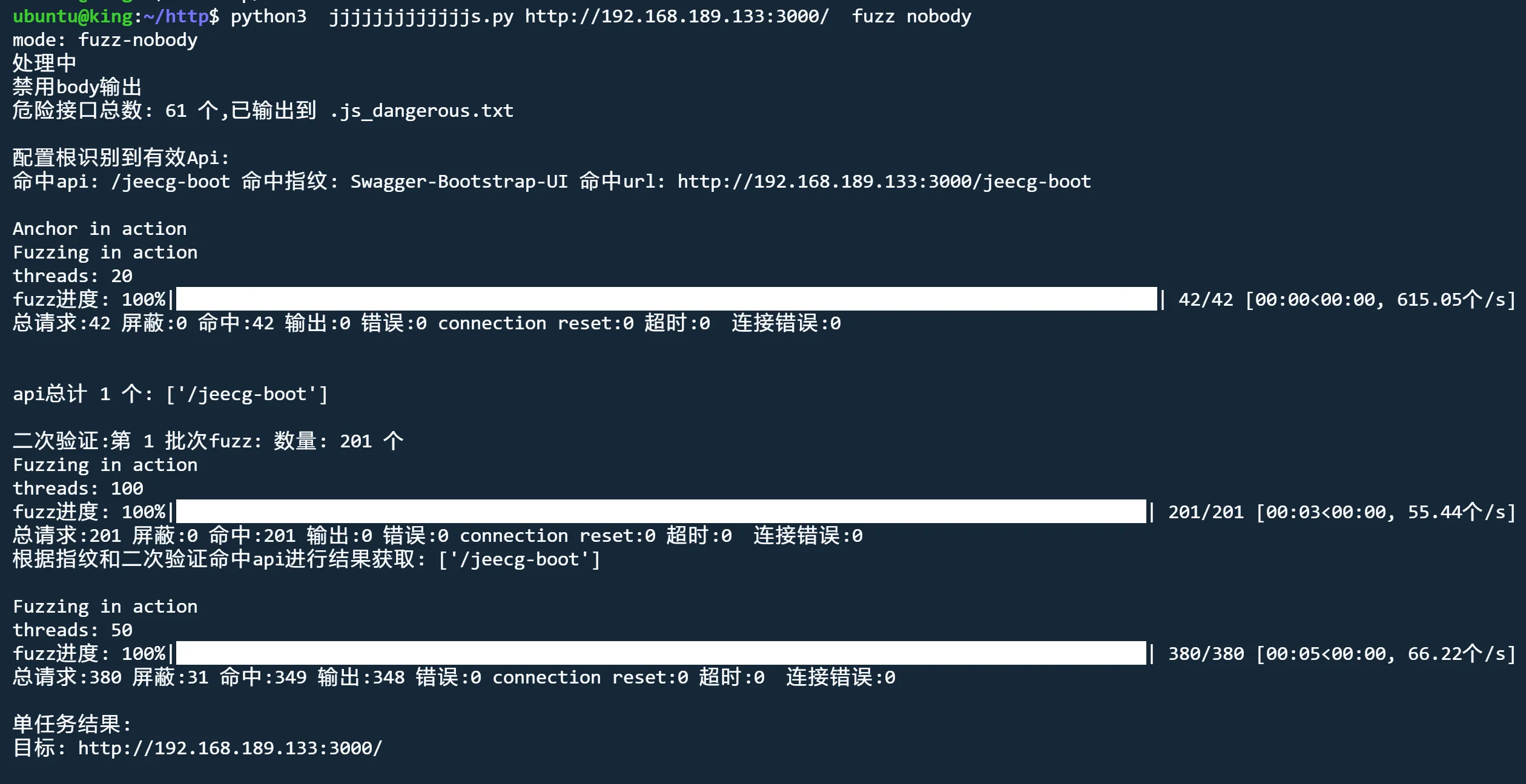
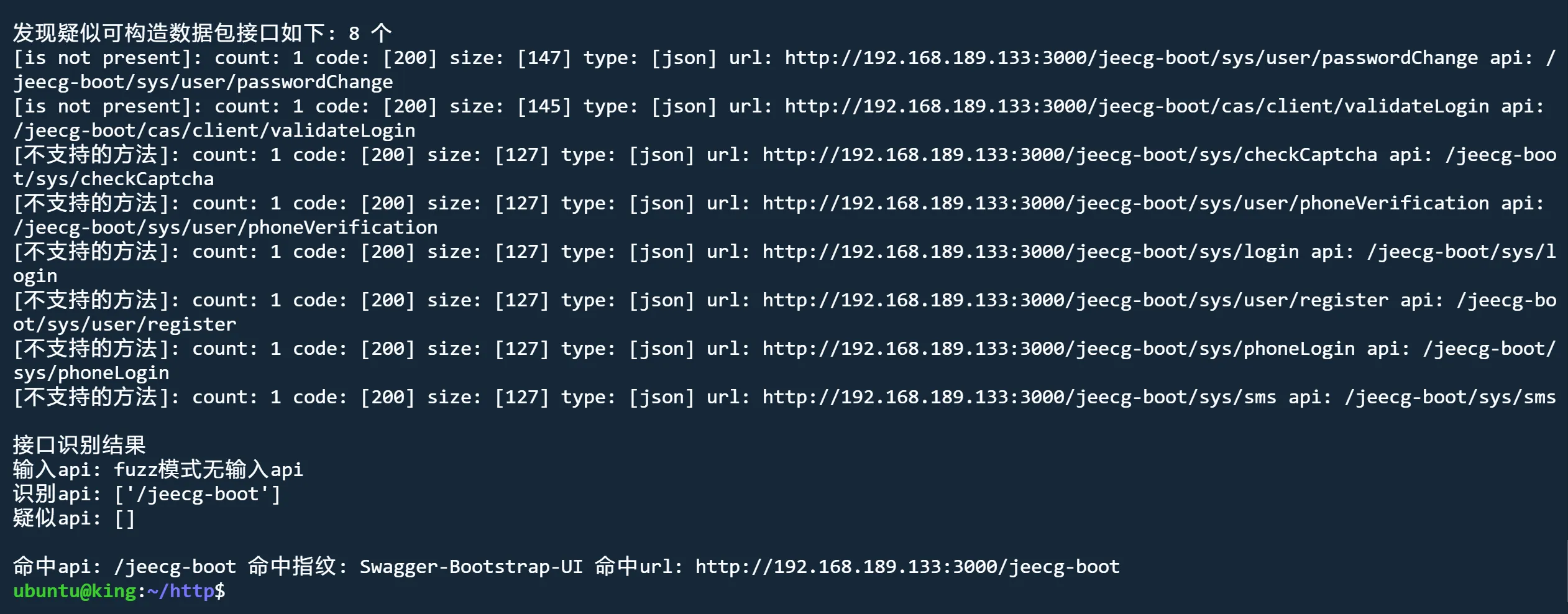
api模式 nofuzz
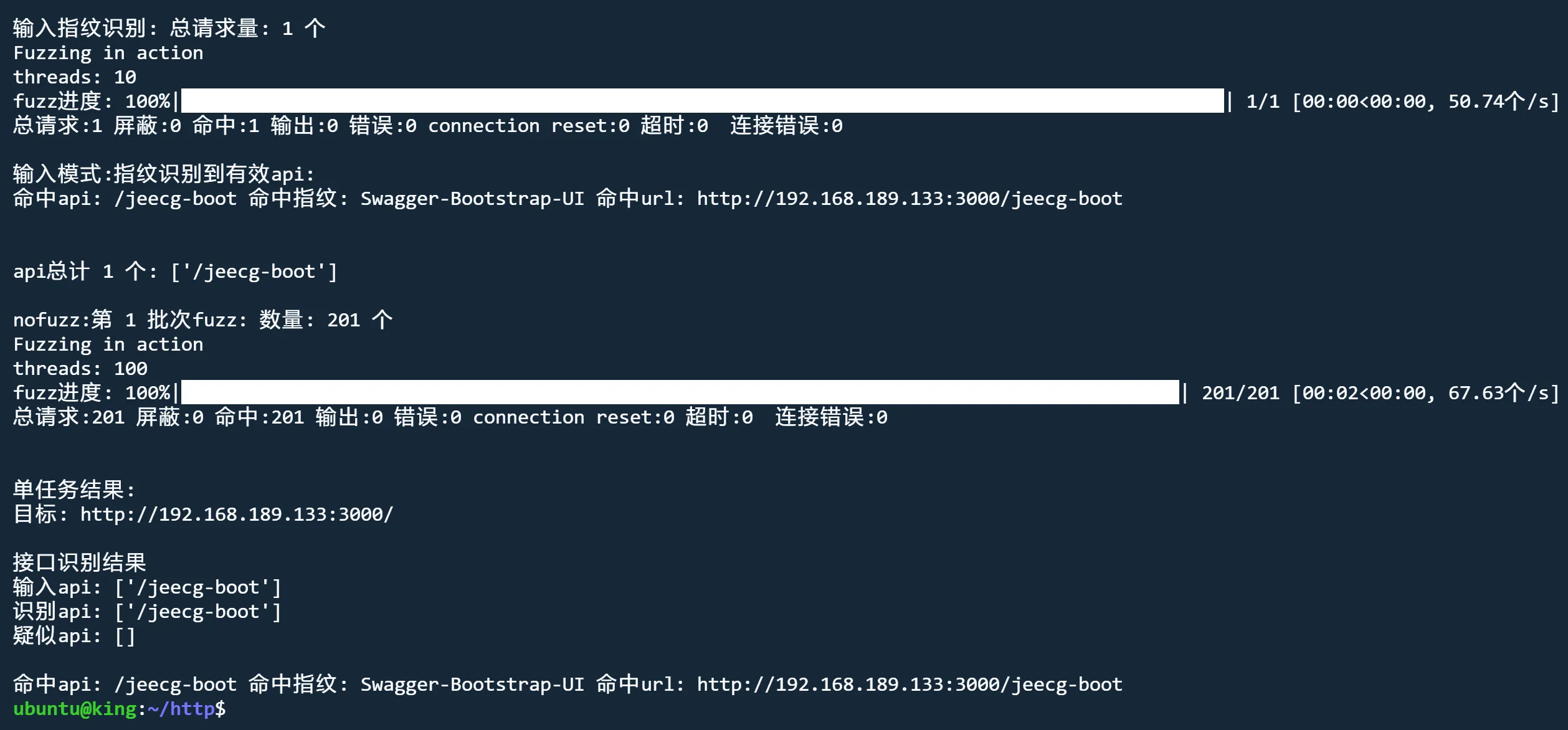
python3 jjjjjjjjjjjjjs.py http://192.168.189.133:3000 api nofuzz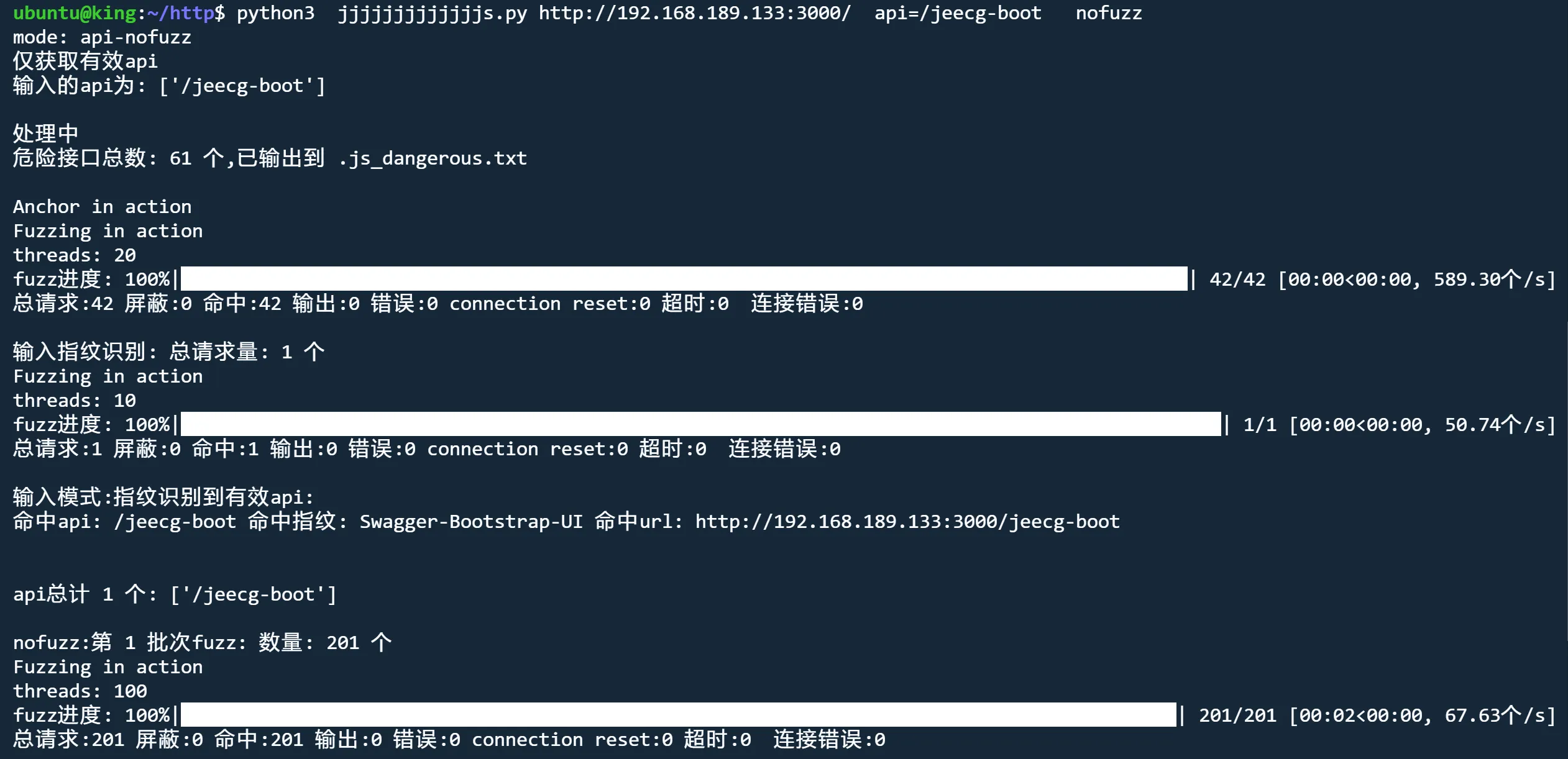
api模式 nobody header
python3 jjjjjjjjjjjjjs.py http://192.168.189.133:3000/ api nobody header='X-Access-Token:eyJxxx'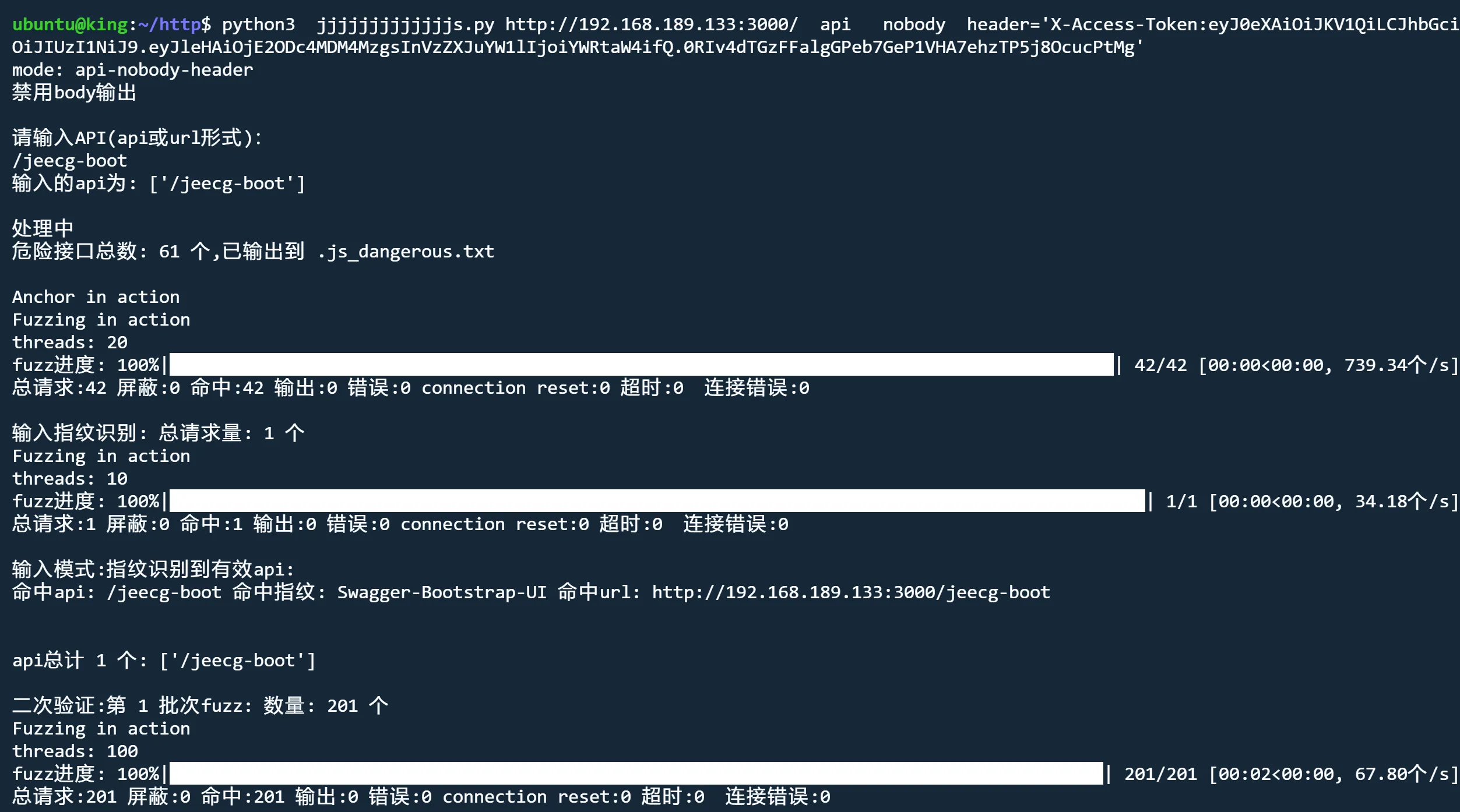
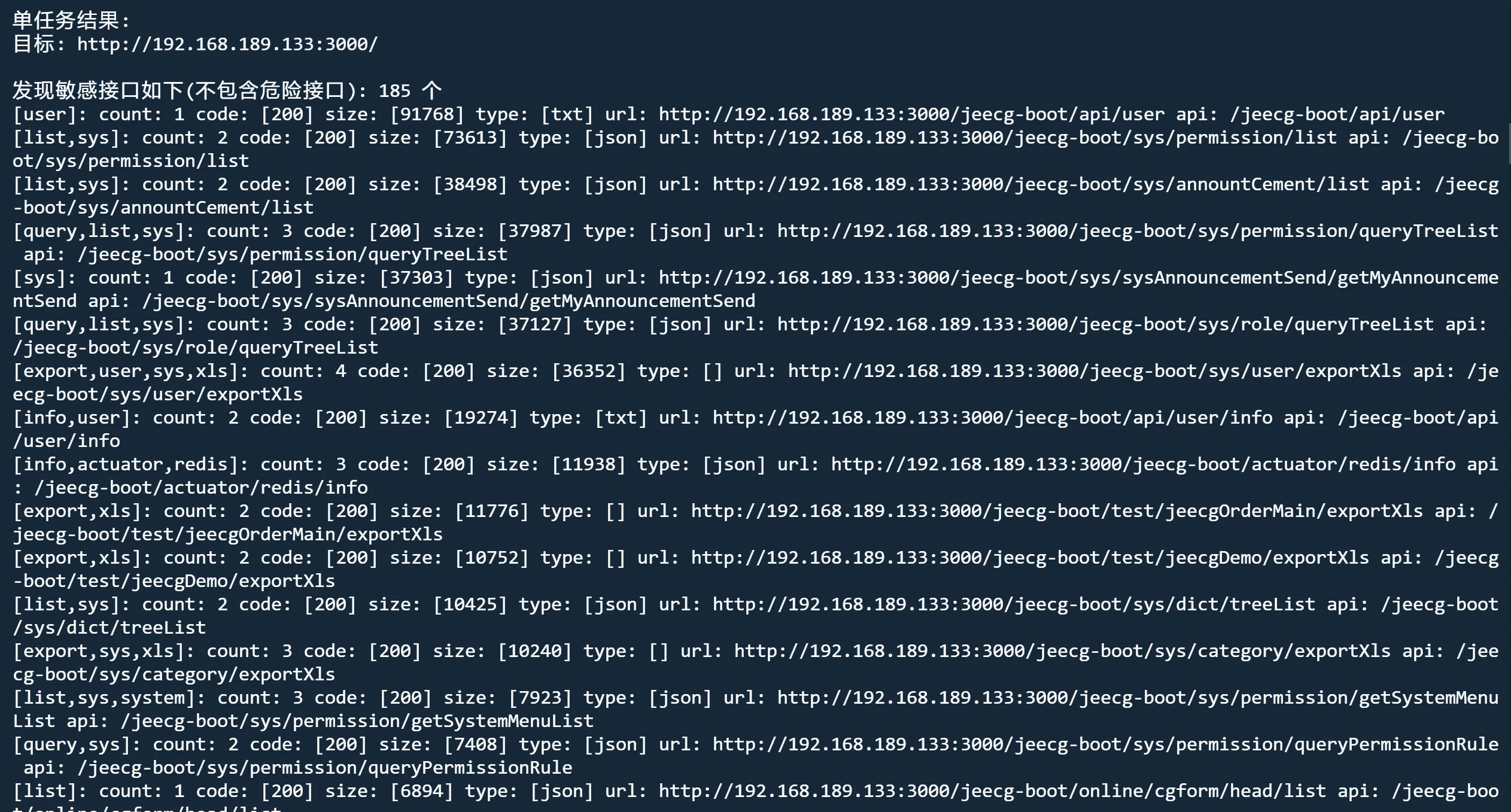
bypass模式 自动实施常见bypass
fuzz模式 nobody bypass
python3 jjjjjjjjjjjjjs.py http://192.168.189.133:3000/ fuzz nobody bypass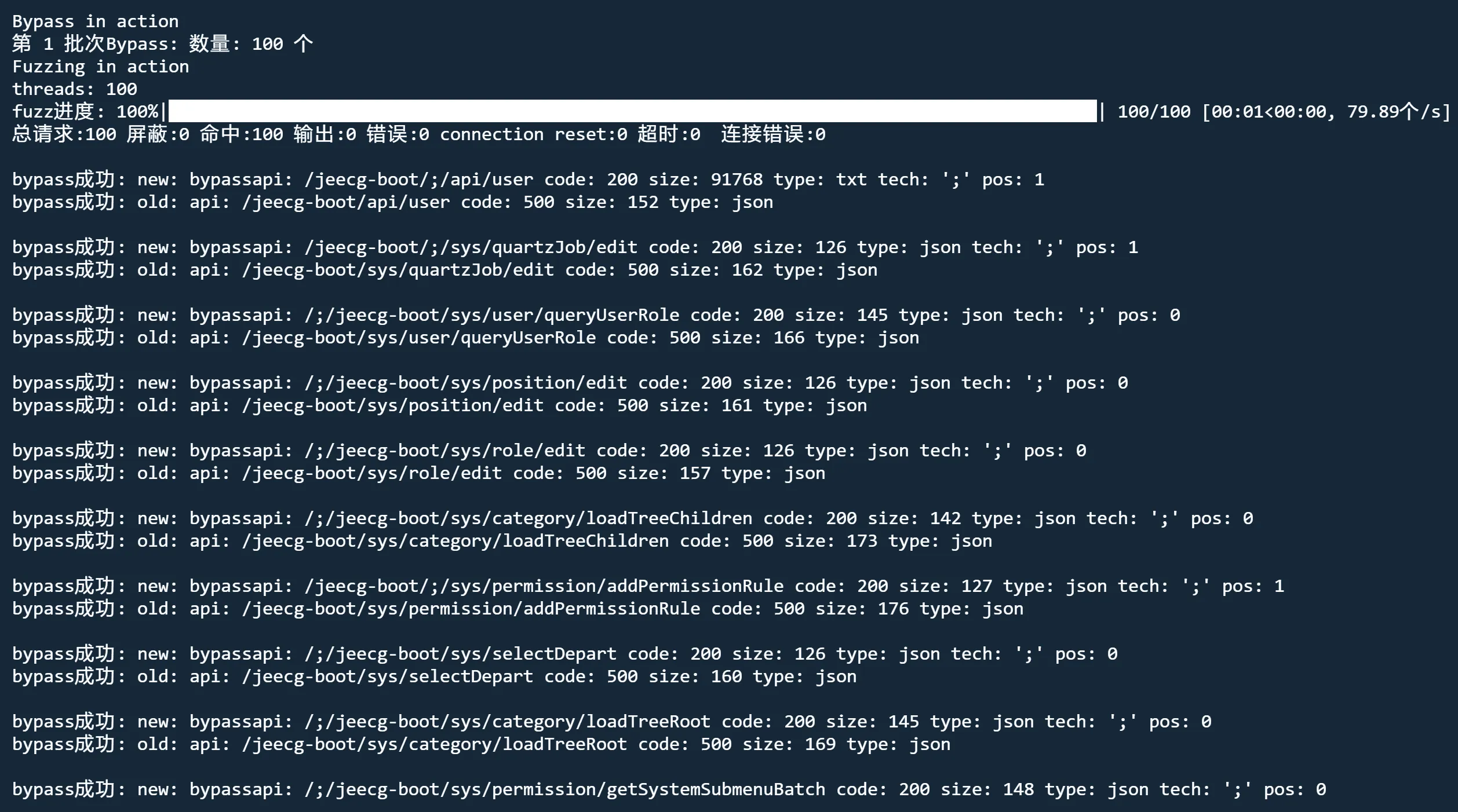
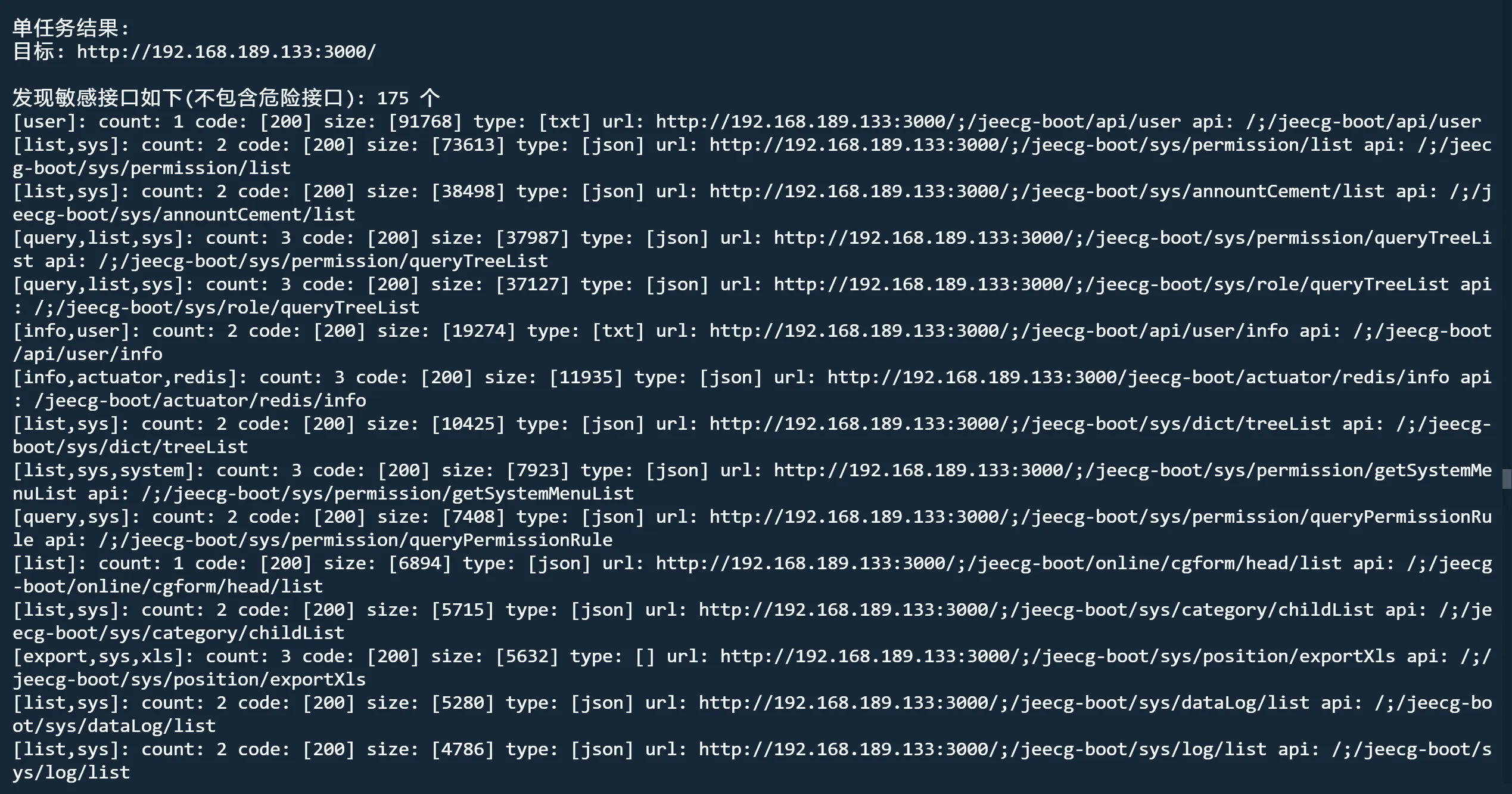
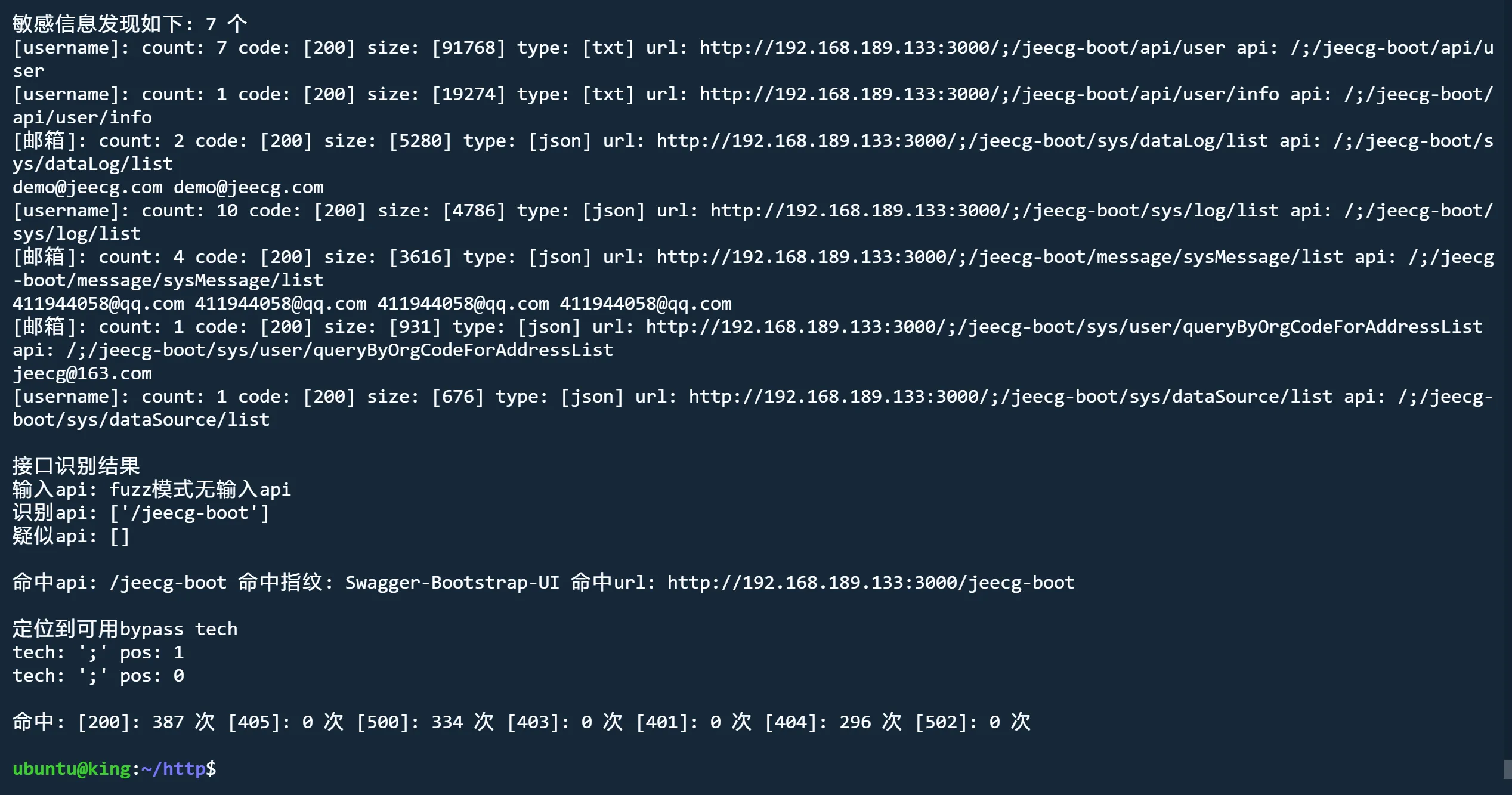
danger模式 解除危险接口限制
python3 jjjjjjjjjjjjjs.py http://192.168.189.133:3000/ fuzz nobody danger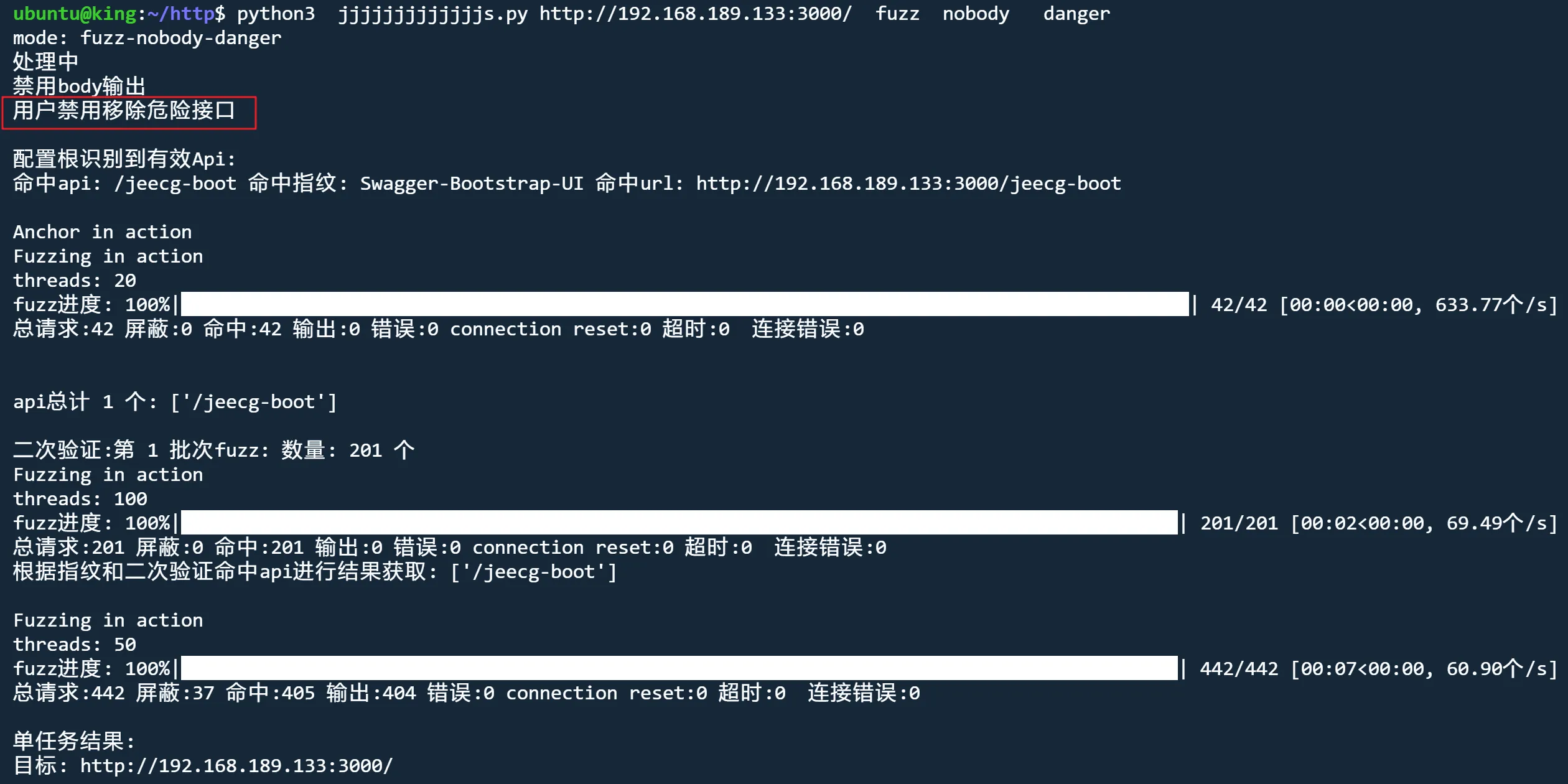
下载地址
项目地址
本文链接:https://apahu.com/455.html
免责声明:本文出现的内容仅用于学习参考,请勿用于非法用途。
版权声明:本站文章资源均源自互联网整理,如侵权请联系处理。
THE END